大脑中神经元声音处理的计算机模型导致人工耳蜗植入的改进
 have developed computer models of the neuronal information processing in the brain stem. This model will allow further development of coding strategies to improve future cochlear implants. Credit: Astrid Eckert")
孩子学习说话依赖于功能性听力。所谓的人工耳蜗通过直接刺激听觉神经,让失聪的人重获听觉。慕尼黑工业大学(TUM)的研究人员正在努力克服目前的技术限制。他们正在研究信号在听觉神经中的执行以及随后在大脑中的神经元处理。利用TUM开发的计算机模型,人工耳蜗制造商改进了他们的设备。
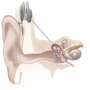
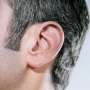
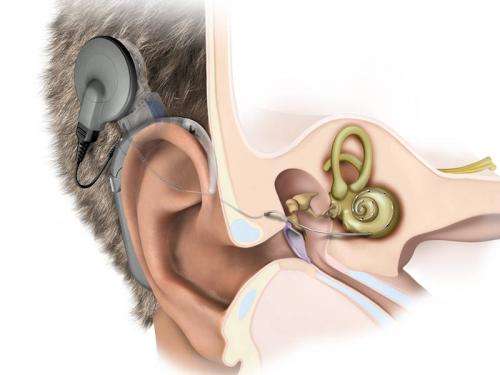
完整的听力是学习说话的先决条件。这就是为什么天生失聪的孩子要尽早植入所谓的人工耳蜗。人工耳蜗由一个语音处理器和一个戴在耳后的发送线圈组成,与实际的植入物一起,一个封装的微处理器被放置在皮肤下,直接刺激耳朵听觉神经通过多达22个触点的电极。
失聪的成年人也可以从人工耳蜗植入中获益。这些装置已经发展成为最成功的神经假体。它们能让病人再次很好地理解口语。但在听音乐或多人同时说话时,这种技术就达到了极限。最初的改善是通过在双耳植入人工耳蜗来实现的。
如果空间听觉能够恢复,将会有进一步的重大发展飞跃。由于我们的两只耳朵相距几厘米,来自一个特定来源的声波通常会先到达一只耳朵。这种差异只有百万分之一秒,但这足以让大脑定位声源。现代微处理器的反应速度已经足够快,但神经脉冲的反应时间要长上100倍左右。为了实现完美的相互作用,需要制定新的策略。
听觉系统建模
声音信息的感知开始于大脑内耳.在那里,毛细胞将机械振动转化为所谓的动作电位,即大脑的语言神经细胞.脑干、中脑和间脑中的神经回路将信号传递到听觉皮层,那里大约有1亿个神经细胞负责创造我们对声音的感知。不幸的是,科学界对这种“编码”仍然知之甚少。
“让植入物更精确地运作,需要更好地适应大脑神经元回路信息处理的策略。这的前提是更好地理解听觉系统,”德国TUM医学工程研究所(IMETUM)生物启发信息处理部门主任Werner Hemmert教授解释道。
基于对神经元的生理测量,他的工作小组成功地建立了内耳和神经元的声学编码的计算机模型信息处理脑干。该模型将允许研究人员进一步开发编码策略,并在听力正常的人以及携带植入物的人身上进行实验测试。
这是研发更好助听器的捷径
适用于耳蜗植入设备与TUM研究人员合作,这些模型是非常有益的评估工具。在计算机上进行初步测试可以节省大量时间和成本。“现在,许多想法的测试速度都快得多。然后,只有最有希望的治疗方法才需要在繁琐的患者试验中进行评估,”Werner Hemmert说。因此,新模型具有显著缩短开发周期的潜力。“这样,患者就能更快地从更好的设备中受益。”
M. Nicoletti, C. Wirtz, W. Hemmert:用人工耳蜗进行声音定位建模,双耳听力技术,施普林格出版社柏林海德堡,2013