基于运动的COVID-19感染建模可以改善公共卫生响应
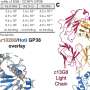
 human movement O-D flows between census tracts in Dane County, (B) Dane County spatial clustering results using the Walktrap network community detection method, (C) the raw cumulative confirmed COVID-19 cases and ratio of per 10,000 people at the census tract level in Dane County by August 14, 2020, (D) human movement O-D flows between census tracts in Milwaukee County, (E) Milwaukee County spatial clustering results using the Walktrap network community detection method, and (F) the raw cumulative confirmed COVID-19 cases and ratio of per 10,000 people at the census tract level in Milwaukee County by August 12, 2020. (COVID-19 confirmed cases data were retrieved from the Wisconsin Department of Health Services.)")
像COVID-19这样的流行病依赖于受感染的人与未受感染的人混合——通常需要其中一人或两人四处走动。一种为大流行感染过程建模的新方法结合了来自智能手机的位置数据,为公共卫生政策制定者提供了一种更准确的图景,即他们社区中的人们是如何混合的,以及在哪里以及如何集中精力。
威斯康星大学麦迪逊分校研究小组成员、地理学教授高嵩说:“大多数COVID-19模型都将一个县或一组人口普查区作为一个同质群体,在许多方面将人口视为一个同质群体。国家科学院院刊.“当我们查看人口普查区的报告时,我们看到一些地区的感染率很高,但邻近地区的确诊病例很低。”
这使得邻近地区的居民似乎不太可能混在一起,因此研究人员将威斯康星州两个人口最多的县——戴恩县和密尔沃基县——的手机出行起源地和目的地的匿名数据交给了一所大学机器学习算法这就把这些县分成了新的次区域。
“该算法利用人口流动的信息,将每个县重新划分为内部流动性较高的更小的子区域。每个新次区域的人们彼此之间的互动是最多的。”
研究人员的新次区域揭示了人口分离,这可能被视为每个县COVID-19感染达到峰值的关键。
“戴恩县最显著的异质性是社区之间年龄结构的差异,”高说。“在密尔沃基县,最显著的区别是种族和民族的多样性。”
这与这些县在2020年夏天暴发疫情的方式一致。戴恩县在其最年轻的次区域努力应对感染率激增的问题,这是由聚集在年轻人群经常光顾的酒吧的感染所致。密尔沃基县的大流行对集中在两个地区的黑人和西班牙裔社区产生了巨大影响,根据流动数据,这两个地区也被确定为相对孤立的次区域。
高说:“考虑到这些子区域内部和之间的流动性的建模让我们更好地理解我们所处的感染情况是如何发生的,有机会调查一些你可能称之为超级传播事件的情况,并可以帮助政策制定者调查为什么某一天的感染率非常高。”他的工作得到了美国国家科学基金会的资助。
该研究团队包括地理学家、数学家、一名流行病学家和通信专家,他们使用该模型来检验随着2020年年中疫情似乎减弱,每个县放松限制的决定。
例如,在5月和6月的步骤中,戴恩县允许企业(包括酒吧)在6月15日开放25%和50%的正常产能。到6月30日,在威斯康辛大学麦迪逊分校邻近的明显年轻的次区域,感染率上升到每千居民11.6例。根据数学建模中包含移动性的方法(不是对照实验),不放松对交互作用的检查将会限制感染比率为3.4‰,是实际价差的三分之一。
整合流动性和人流量数据可以帮助公共卫生机构确定其社区需要解决的独特方面,以阻止大流行病毒的传播。
“我们可以根据不同类型的异质性,设计针对不同地区的政策,而不是实施一刀切的政策,”高说。