利用人工智能改善用药错误的报告
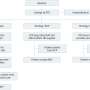
 the SOM nodes are arbitrarily positioned in the data space. The node (highlighted in yellow) which is nearest to the training datum is selected. It is moved towards the training datum, as (to a lesser extent) are its neighbors on the grid. After many iterations, the grid tends to approximate the data distribution (right). Credit: DOI: 10.1016/j.array.2020.100049")
一种新颖的机器学习方法已经找出了导致护士在分配药物时报告或不报告非关键错误的因素
医疗事故比许多人想象的要普遍得多,最常见的类型是配药。然而,非关键错误很少被报告。由美国爱荷华大学的Renjie Hu领导的一个跨学科科学家小组开发了一种计算方法,用于预测使护士更有可能报告错误的因素。这项工作以开放获取的方式发表在Elsevier期刊上数组.
更多的美国人死于医疗事故比死于乳腺癌、艾滋病和车祸的人数加起来还要多。然而,这些事件只是冰山一角;所有类型的医疗差错,包括用药差错,都严重漏报,除非它们对有关患者造成严重伤害。实际报告率甚至可能低至5%。
在一家典型的医院里,护士参与管理大约40%的药物;即使他们自己不给药,他们也经常能够观察到给药的过程。尽管责任在他们身上,但他们列出了许多不报告错误的理由,特别是在没有造成严重损害的情况下。其中包括害怕来自经理和同事的指责和报复。
有许多因素可能会影响,在任何给定的事件后,是否护士相关人员将报告错误。这些因素包括护士与管理者的关系、护士对机构的归属感程度、信任问题以及基本的人口统计学特征。
Hu和他的同事开发的计算方法使用了两种不同的机器学习方法来搜索,然后可视化数据中的模式,这些模式表明哪些因素在不同情况下决定护士的行为最重要。“这是一种新颖、强大的方法,能够将非线性分析和可视化结合起来,揭示数据中的非线性因素(如人类行为),并指导高级医院工作人员改善他们的管理,”胡说。
研究人员考虑了三种类型药物治疗越来越严重的错误:错误被发现并在犯之前改正;犯了错误但对病人没有潜在伤害的地方;以及病人可能受伤但没有受伤的地方。他们收集了有关护士、他们的经理和机构的相关数据,以及他们报告这三种类型疾病的可能性错误从调查中,并平行使用神经网络确定那些与报告错误的高可能性和低可能性最相关的变量。
最具预测性的变量是使用另一种机器学习技术在彩色网格上可视化的:自组织地图。“这种可视化分析为我们提供了对选定变量的全面分析,”Hu补充道。在最不严重的错误中,护士的判断最容易受到同事态度的影响,而在更严重的错误中,管理者的态度更重要。
更多信息:Renjie Hu等人,使用机器学习识别护士报告用药错误意愿的顶级预测因素,数组(2020)。DOI: 10.1016 / j.array.2020.100049