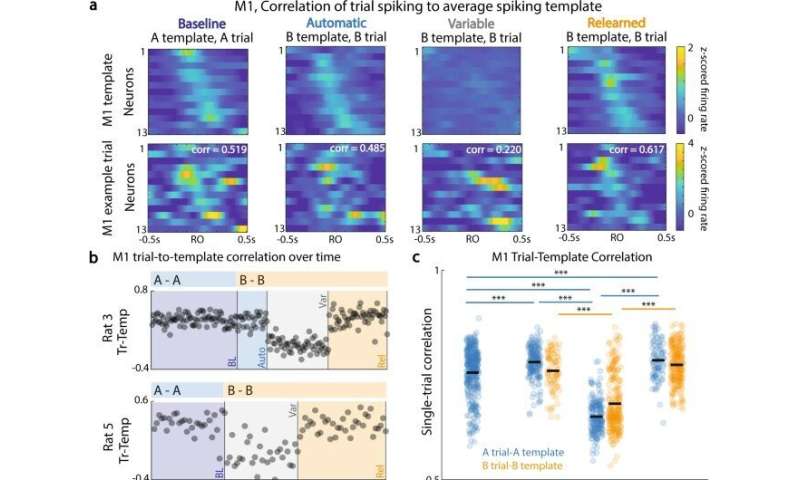
用多日时间重新学习一项自动技能。(a)自动伸手抓握装置。门打开后(用声音表示),大鼠会从缝隙中取出小球。插图中的M1(绿色)和DLS(灰色)位置。(b)再学习范式。老鼠被过度训练以到达位置A(左图)。然后小球移动到位置B,并继续训练(中,右)。(c)第一次到达的终点。上图:示例动物,跨试验的端点x位置直方图。下图:示例到达轨迹和端点位置相对于颗粒位置(大黑色圆圈)的相同会话(顶部)。 (d) Decay in reaches to A. Percentage of trials in a session with first reach (R1) to location A, as compared to low-amplitude (short, S) reaches and/or reaches to location B. (e) For those trials with multiple reaches, within-trial updating for reaches after the first were classified into short (S), old (A), or new (B) reaches. (f) Example x-trajectory of paw during a trial, with reach onset marked; r1 and r2 are the first and second reach onsets, respectively. g Reach type after first reach, for trials with multiple reaches. For all reaches after the first reach in a trial, proportion of A, B, or S reaches. Data are presented as mean values ± SEM. h Following an inaccurate trial, we classified the first reach type of the subsequent trial. i Reach type after inaccurate reach to A on previous trial. Data are presented as mean values ± SEM. *<0.05; **<0.01; ***<0.001, ANOVA, Tukey-Kramer post hoc test. Credit:自然通讯(2022)。DOI: 10.1038 / s41467 - 022 - 30069 - 1
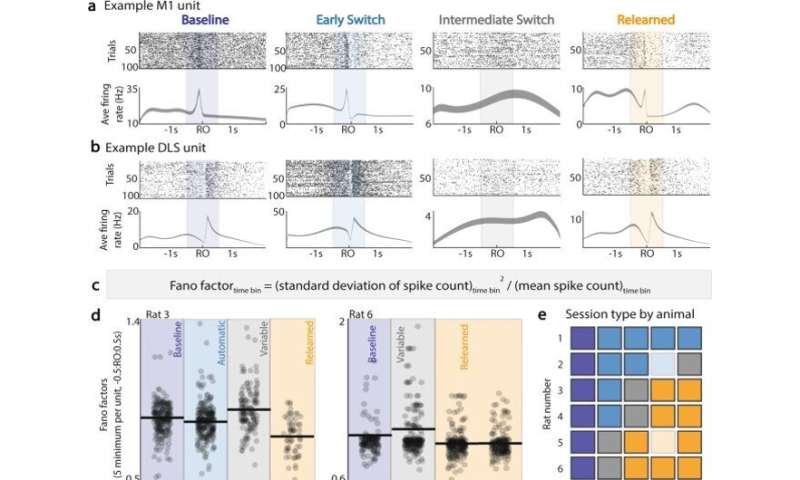
在探索过程中,到达锁定M1和DLS单位尖峰故障。(a)顶部:跨会话的单个M1单元†的光栅(跨天的相同通道)。底部:在第一次到达时- 2秒到2秒内的试验平均发射速率(平均值±SEM)。(b)与(a)相同,用于DLS单元。†(c)确定每个单元每个时段的Fano因子的公式。(d)对于两个示例动物,在具有代表性的会话中,在第一次到达发病前后- 0.5 s至0.5 s内,每单位5个最小Fano因子。(e)基于Fano因素的会话类型重新分类:靛蓝=基线,蓝色=自动(切换后,没有Fano因素变化),灰色=变量(Fano因素最大增加),橙色=重新学习。浅蓝色/浅橙色=由于记录过程中的数据损坏而未分析两个会话。(f)跨会话类型,第一次到达A的试验(蓝点)和第一次到达B的试验(橙点)在到达开始前后的M1单位峰值试验平均调制;峰值调制是在z计分单元在整个会话中发射后计算的。 (g) Same as (f), for DLS units. (h) Change in proportion of first reach to A in a session, relative to proportion of first reach to A in previous session; grouped by session type across all animals, all sessions. i Proportion of first reach to B in a session, grouped by session type across all animals, all sessions. †Unit may not be the same across sessions. *<0.05, **<0.01, ***<0.001, linear mixed effects model, Bonferroni-corrected significance. Credit:自然通讯(2022)。DOI: 10.1038 / s41467 - 022 - 30069 - 1
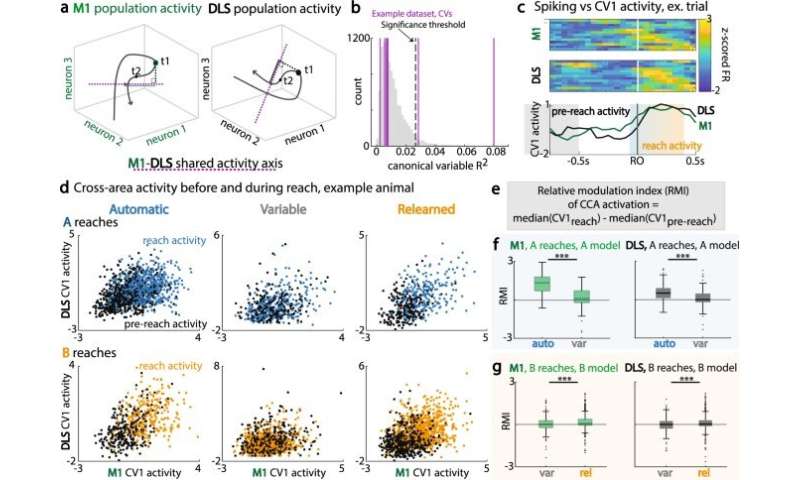
M1-DLS跨区域子空间调制的变化。(a)典型相关分析(CCA):识别M1与DLS活动之间相关性最大的轴(紫色虚线),M1种群活动(左,绿色)和DLS种群活动(右,黑色)在t1时刻的预测种群活动的示例值(共享轴上的实线)。(b)用于识别显著典型变量(CV)轴的R2值的示例自举洗牌分布。(c)顶部:单次试验M1峰值活动。中间:单次试验DLS尖峰活动。下图:相应的单次试验M1(绿色)和DLS(黑色)沿着CV1激活。预到达时间(灰色)为第一次到达前的−1 ~−0.5 s。到达周期(蓝橙色)为−0.1 s到0.4 s左右的第一次到达开始。(d)跨会话类型(如动物)的A组试验(上排)和B组试验(下排),到达前(黑色)和到达时(彩色)M1和DLS的跨区域活动。(e) CCA激活的相对调制指数(RMI)方程,比较到达期和到达前期。 (f) RMI for trials with first reach to A, for M1 activations (left, green) and DLS activations (right, green), across automatic and variable sessions. R1 to A, M1 and DLS RMI: auto, n = 220 trials; var, n = 95 trials. Data are presented as box plots with 25th, 50th, and 75th percentiles. (g) Same as (f), for trials with first reach to B, across variable and relearned sessions. R1 to B, M1 and DLS RMI: var, n = 150 trials; rel, n = 464 trials. Data are presented as box plots with 25th, 50th, and 75th percentiles. *<0.05; **<0.01; ***<0.001, linear mixed effects model, Bonferroni-corrected significance. Credit:自然通讯(2022)。DOI: 10.1038 / s41467 - 022 - 30069 - 1
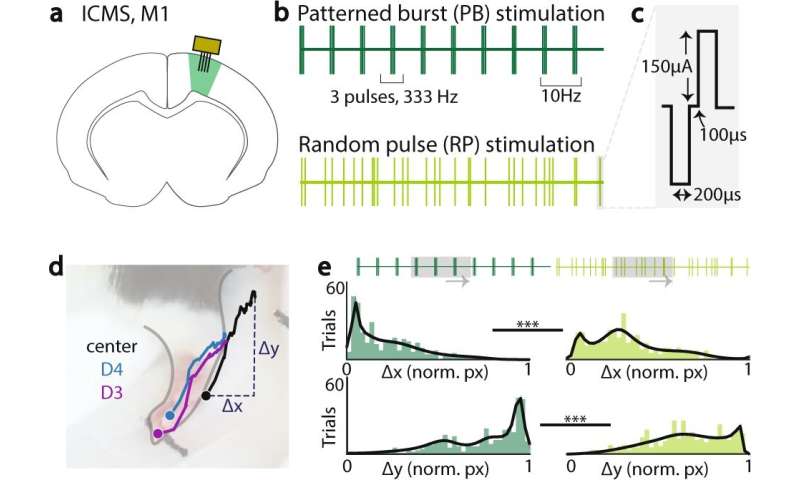
刺激变异性在驱动上肢运动变异性中的作用。a刺激位置,通过微线阵列连接到M1以识别引发前肢运动的区域。b刺激传递的模式,与总电荷传递的平衡。模式脉冲刺激(顶部,PB)由333 Hz三联体组成,三联体频率为10 Hz。随机脉冲刺激(底部,RP)由单脉冲组成,随机时间为30 Hz。每次刺激持续1秒,每次总共30次脉冲。c刺激脉冲参数,采用200 μA双相脉冲,每相200 μs,相间间隔100 μs。d爪侧视图:标记用于监督运动跟踪的肢体标记:4号手指的尖端(D4,蓝色),3号手指的尖端(D3,紫色)和爪的中心(中心,黑色)。每个试验的终点位置(Δx, Δy)相对于试验窗口的起始位置计算,并通过动物跨刺激条件归一化。e例子动物直方图的标准化Δx(上)和Δy(下)的爪子的中心通过图案爆发刺激试验(左)和随机脉冲刺激试验(右)。 Gray boxes show an example 300 ms window with identical number of pulses. Kolmogorov-Smirnov test for two samples in this example animal, center of paw, p = 1.8e−11; *<0.05; **<0.01; ***<0.001, Kolmogorov-Smirnov test for two samples. Credit:自然通讯(2022)。DOI: 10.1038 / s41467 - 022 - 30069 - 1
 Automated reach-to-grasp setup. After the door opens (signaled by a tone), the rat reaches through a slit to retrieve the pellet. M1 (green) and DLS (gray) locations in inset. (b) Relearning paradigm. Rats are overtrained to reach to location A (left). Then pellet moved to location B with continued training (middle, right). (c) Endpoint of first reaches. Top: example animal, histogram of endpoint x-position, across trials. Bottom: example reach trajectories and endpoint locations relative to pellet location (large black circle) for same sessions as (top). (d) Decay in reaches to A. Percentage of trials in a session with first reach (R1) to location A, as compared to low-amplitude (short, S) reaches and/or reaches to location B. (e) For those trials with multiple reaches, within-trial updating for reaches after the first were classified into short (S), old (A), or new (B) reaches. (f) Example x-trajectory of paw during a trial, with reach onset marked; r1 and r2 are the first and second reach onsets, respectively. g Reach type after first reach, for trials with multiple reaches. For all reaches after the first reach in a trial, proportion of A, B, or S reaches. Data are presented as mean values ± SEM. h Following an inaccurate trial, we classified the first reach type of the subsequent trial. i Reach type after inaccurate reach to A on previous trial. Data are presented as mean values ± SEM. *<0.05; **<0.01; ***<0.001, ANOVA, Tukey-Kramer post hoc test. Credit: <i>Nature Communications</i> (2022). DOI: 10.1038/s41467-022-30069-1")