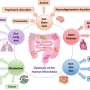
肠道菌群元分析中的批处理效应和挑战。a,多个数据集集成中的常见挑战。b,基于7项研究中对照样本(开放点)和CRC样本(填充点)相对丰度的主坐标分析。箱形图表示七个研究之间或病例组与对照组之间的差异。在箱形图中:中心线,中位数;四分位范围(IQR;介于第25百分位和第75百分位之间);须,1.5 × IQR;点,离群值。双侧Wilcoxon检验或Kruskal-Wallis秩和检验。 ***P < 0.001; **P < 0.01; *P < 0.05. c, The number of differentially abundant bacteria with a two-sided Wilcoxon test in each study. The numbers on the leaves correspond to the unique differential bacteria of each study, and differential bacteria shared by multiple studies are shown in the central circle. d, Top: the bar height represents the meta-analysis significance of gut microbial genera derived from blocked Wilcoxon tests (top). Bottom: heatmap representing the fold change within individual studies. Bacteria are ordered by meta-analysis significance. e, The distribution of edges under different thresholds of microbial networks constructed from seven CRC studies. Inset: average degree under different thresholds; different colors of lines represent seven CRC studies, respectively. The gray regions indicate the 95% confidence intervals. Credit:自然计算科学(2022)。DOI: 10.1038 / s43588 - 022 - 00247 - 8
 and CRC samples (filled points) from seven studies. Box plots represent differences among seven studies or between case and control groups. In the box plots: center line, median; box, interquartile range (IQR; the range between the 25th and 75th percentiles); whiskers, 1.5 × IQR; dots, outliers. Two-sided Wilcoxon test or Kruskal–Wallis rank sum test. ***P < 0.001; **P < 0.01; *P < 0.05. c, The number of differentially abundant bacteria with a two-sided Wilcoxon test in each study. The numbers on the leaves correspond to the unique differential bacteria of each study, and differential bacteria shared by multiple studies are shown in the central circle. d, Top: the bar height represents the meta-analysis significance of gut microbial genera derived from blocked Wilcoxon tests (top). Bottom: heatmap representing the fold change within individual studies. Bacteria are ordered by meta-analysis significance. e, The distribution of edges under different thresholds of microbial networks constructed from seven CRC studies. Inset: average degree under different thresholds; different colors of lines represent seven CRC studies, respectively. The gray regions indicate the 95% confidence intervals. Credit: <i>Nature Computational Science</i> (2022). DOI: 10.1038/s43588-022-00247-8")