专门的大脑区域识别声音的线索,不涉及演讲
 and do not respond to non-voice acoustic signals. Credit: Kyle Rupp and Taylor Abel")
大脑的特定部位识别复杂的线索在人类的声音,不涉及演讲,如哭、咳嗽或gasping-found匹兹堡大学的研究人员。
在今天发表的一篇论文公共科学图书馆生物学科学家表明,听觉皮层的两个领域专业的认识人类的声音听起来,与演讲,不带语言的意义。相反,他们帮助我们应对声音提示,允许人们立刻说话人的识别特征,如性别、大致年龄、情绪甚至身高都没有看到他们。
“语音知觉类似于人类如何识别不同的面孔,“资深作者泰勒伯说,医学博士神经外科助理教授皮特。“声音不包括演讲的例子中,婴儿的哭声,咳嗽,呻吟或exclamations-allow我们获得很多信息关于人的声音在缺乏其他的信息的人。”
人类生活在一个充满声音的世界里,噪音来自环境的塑造我们每日与环境的互动和其他人。尽管语言是人类交流的一个独特方面没有直接的类似物动物世界,人们不单单依靠演讲来传达听觉信息。
交际方面的的声音有至关重要的作用在我们的通信工具箱,扩大人类准确表达自己的能力和动态。表达式是潜意识的一部分,它可能是故意调制的一部分演讲者传达一个广泛的情绪,比如快乐、恐惧或厌恶。
人类是天生的能力语音识别——事实上,婴儿能够识别他们的母亲的声音虽然仍在womb-but能力是动态的,在青春期和继续发展。
亚伯,他是练习儿科神经外科医生专门从事癫痫,有一个独特的机会来看看如何人类的大脑回应的声音。
确定的地区大脑负责产生癫痫发作在某些癫痫患者,神经外科医生可能临时电极植入大脑仔细记录的电信号。这种做法允许医生精确定位的发作并最终消除这部分的大脑,同时保留周围的健康组织。
八个癫痫患者同意参与研究亚伯和他的团队使用的植入电极来测量领域的听觉皮层反应时声音sounds-grunts,唧唧的声音,laughs-were呈现给病人。
使用直接的组合大脑记录和计算模型,调查人员能够详细描述以前所未有的声音表示如何发展随着时间的推移和解码,当一个声音一直基于听觉皮层的神经活动模式。
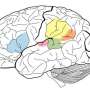
研究人员发现,大部分来自两个区域的活动听觉皮层大脑的折叠灰质被称为颞回(STG)和颞上沟(STS)。脑成像研究表明,STG前和STS对声音处理是很重要的,这项研究表明这些地区代表的声音作为一种独特的声音类别而不是简单地代表的物理或声学方面的声音。
这个新知识的组织语音识别系统连接我们的大脑将使研究人员能够更好地理解神经系统疾病如精神分裂症和孤独症,语音知觉改变或失踪,甚至帮助创造更好的语音助理设备,目前擅长识别演讲但不善于区分几个扬声器。
凯尔·拉普博士是该论文的第一作者;额外的作者茉莉花Hect、麦迪逊媚Avniel Ghuman,博士,博士和Bharath•钱德拉塞卡兰从皮特;洛丽·霍尔特,卡内基梅隆大学的博士。
进一步探索