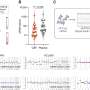
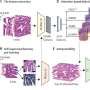
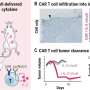
福尔马林暴露的突变特征。C>T ffpe突变数随着福尔马林固定时间的增加而增加。我们观察到研究1(固定组)中未修复和修复的ffpe样本均有此增加。仅FFPE突变是指仅在FFPE中发现而未在FF样本或已知生殖系数据库中发现的突变。柱状高度表示n = 3例患者的平均C>T计数,个体计数用黑点标记。b使用80通道光谱(non-T>C)对未修复的ffpe和修复的ffpe样品观察到一致且可分离的突变模式。我们使用t-SNE对来自研究1和研究2的归一化80通道突变谱(n = 110)进行聚类(参见方法)。c T> c突变未观察到一致和可分离的突变模式。我们使用T - sne将研究1和研究2的归一化T>C突变谱(n = 110)聚类。d我们推导的FFPE签名与已知COSMIC SBS签名的比较。 e, f Unrepaired signature is highly similar to SBS30 (e) and repaired signature is highly similar to SBS1 (f). We treated T>C features as missing data due to the strong batch-effect found in study 1, which is also observed in a few other studies shown in Supplementary Table 1 and therefore they were assigned to zeros. We noted that zero values are approximately close to the true T>C mutation probabilities in FFPE datasets without this batch-effect (Supplementary Fig. 6f). Error bars indicate the standard deviation in n = 55 independent samples with top 50% density in t-SNE cluster (see Methods). g, h Large variability in T>C mutation channels. We derived the T>C patterns using the same methods applied in (e, f). The error bar showed the standard deviations in n = 55 independent samples with top 50% density within the t-SNE (see Methods). Credit:自然通讯(2022)。DOI: 10.1038 / s41467 - 022 - 32041 - 5
. FFPE-only mutations refer to mutations that are only discovered in FFPE but not in FF samples or known germline databases. The bar height represents the average C>T count in n = 3 patients, and the individual counts are marked as black dots. b Consistent and separable mutational patterns observed for unrepaired-FFPE and for repaired-FFPE samples using 80-channel spectrum (non-T>C). We clustered the normalized 80-channel mutation profiles (n = 110) from study 1 and 2 using t-SNE (see Methods). c No consistent and separable mutational patterns observed for T>C mutations. We clustered the normalized T>C mutation profiles (n = 110) from study 1 and 2 using t-SNE. d Comparison of our derived FFPE signatures to known COSMIC SBS signatures. e, f Unrepaired signature is highly similar to SBS30 (e) and repaired signature is highly similar to SBS1 (f). We treated T>C features as missing data due to the strong batch-effect found in study 1, which is also observed in a few other studies shown in Supplementary Table 1 and therefore they were assigned to zeros. We noted that zero values are approximately close to the true T>C mutation probabilities in FFPE datasets without this batch-effect (Supplementary Fig. 6f). Error bars indicate the standard deviation in n = 55 independent samples with top 50% density in t-SNE cluster (see Methods). g, h Large variability in T>C mutation channels. We derived the T>C patterns using the same methods applied in (e, f). The error bar showed the standard deviations in n = 55 independent samples with top 50% density within the t-SNE (see Methods). Credit: Nature Communications (2022). DOI: 10.1038/s41467-022-32041-5")