没有标签?没问题!新工具克服了临床AI设计中的主要障碍

哈佛医学院的科学家和斯坦福大学的同事开发了一种人工智能诊断工具,可以直接从临床报告中包含的自然语言描述中检测出胸部x光片上的疾病。
这一步被认为是临床AI设计的重大进步,因为目前大多数AI模型都需要人工费力地注释大量数据,然后将标记数据输入到模型中进行训练。
一份关于这项工作的报告于9月15日发表在自然生物医学工程,显示,这个名为CheXzero的模型在检测胸部x光片病理的能力上与人类放射科医生不相上下。
该团队已经为模型编写了代码公开的其他研究人员。
大多数人工智能模型在“训练”过程中需要标记数据集,这样它们才能学会正确识别病理。这一过程对于医学图像判读任务来说尤其繁重,因为它涉及到人类临床医生的大规模注释,这通常是昂贵和耗时的。例如,要给一个胸部x光数据集贴上标签,放射科专家将不得不逐个查看数十万张x光图像,并明确地用检测到的条件标注每张图像。虽然最近的AI模型试图通过在“预训练”阶段从未标记的数据中学习来解决这个标记瓶颈,但它们最终需要对标记数据进行微调以实现高性能。
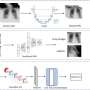
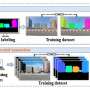
相比之下,新模型是自我监督的,从某种意义上说,它更独立地学习,不需要在训练前后手工标记数据。该模型仅依赖胸部x光片和x光片报告中的英文注释。
“我们正生活在下一代医疗AI模型的早期,这些模型能够通过直接从文本中学习来执行灵活的任务,”该研究的首席研究员Pranav Rajpurkar说,他是HMS布拉瓦特尼克研究所生物医学信息学的助理教授。“到目前为止,大多数人工智能模型都依赖于对大量数据(10万张图像)的人工注释来实现高性能。我们的方法不需要这种特定于疾病的注释。
Rajpurkar补充道:“有了CheXzero,人们只需给模型输入一张胸部x光片和相应的放射报告,它就会知道报告中的图像和文本应该被认为是相似的——换句话说,它会学习将胸部x光片与相关报告相匹配。”“该模型最终能够了解非结构化文本中的概念如何与图像中的视觉模式相对应。”
该模型是在一个公开的数据集包含超过37.7万张胸部x光片和超过22.7万份相应的临床记录。然后,它的性能在两组不同的胸部x光数据集和相应的记录上进行了测试,这些数据收集自两个不同的机构,其中一个机构在不同的国家。数据集的多样性是为了确保模型在面对可能使用不同术语描述同一发现的临床记录时同样表现良好。
在测试中,CheXzero成功地识别了那些没有被人类临床医生明确注释的病理。它优于其他自我监督的人工智能工具,其准确性与人类放射科医生相似。
研究人员说,这种方法最终可以应用于x光以外的成像方式,包括CT扫描、核磁共振和超声心动图。
“CheXzero表明,复杂医学图像解读的准确性不再需要依赖于大型标记数据集,”该研究的共同第一作者Ekin Tiu说本科生他是斯坦福大学的教授,也是HMS的访问研究员。“我们以胸部x光片为例,但在现实中,CheXzero的能力可以推广到大量的医疗环境中,在这些环境中,非结构化数据是标准的,而且恰恰体现了绕过困扰医疗机器学习领域的大规模标签瓶颈的希望。”
进一步探索