研究人员发现,病史可能有助于预测幼儿的自闭症
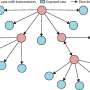
 of random forest models with variables sequentially included following the order of the median of Gini importance index from 50 replications. Credit: <i>BMJ Health Care Inform</i> (2022). DOI: 10.1136/bmjhci-2022-100544")
医疗保险索赔可能不仅仅是帮助支付健康问题;根据宾夕法尼亚州立大学跨学科研究团队在《科学》杂志上发表的新发现,它们可以帮助预测它们英国医学杂志健康与护理信息学.研究人员开发了机器学习模型,评估数百个临床变量之间的联系,包括医生就诊和看似不相关的医疗条件的医疗保健服务,以预测幼儿患自闭症谱系障碍的可能性。
通讯作者、宾夕法尼亚州立工程学院工业与制造工程助理教授陈秋实说:“保险理赔数据是去识别的,在营销扫描数据集中广泛可用,它提供了关于患者的全面的纵向医疗细节。”
“科学文献该领域的研究表明自闭症谱系障碍也往往有较高的临床症状发生率,如不同类型的感染、胃肠道问题、癫痫发作以及行为指征。那些症状不是原因自闭症但通常在自闭症儿童中表现出来尤其是在年幼的时候,所以我们受到启发合成医疗信息来量化和预测相关的可能性。”
研究人员将数据输入机器学习模型,训练它评估数百个变量,以找到与自闭症谱系障碍可能性增加有关的相关性。
“自闭症谱系障碍是一种发育障碍,”合著者刘国栋说,他是宾夕法尼亚州立医学院的公共卫生科学、精神病学、行为健康和儿科学的副教授。bob电竞“临床医生需要观察和多次筛查才能做出诊断。这个过程通常很漫长,许多孩子错过了早期干预的机会,而早期干预是改善结果最有效的方法。”
常用的筛查工具之一,帮助鉴别年幼的孩子患有自闭症谱系障碍可能性较高的儿童被称为“蹒跚学步自闭症修正清单”(M-CHAT),该清单通常在18和24个月大的正常儿童例行检查时给出。
它包括20个问题,关注与眼神交流、社会互动和一些身体里程碑(如走路)有关的行为。监护人的回答是根据他们的观察得出的,但陈说,这些年龄段的发育差异很大,所以这个工具可能会把孩子识别错。因此,儿童通常要到四五岁时才能得到正式诊断,这意味着他们错过了多年可能的早期干预。
“我们的新模型量化了识别的总和风险因素一起告知可能性水平,已经可以与现有的筛查工具相比,在某些情况下甚至略好,”陈说。“当我们将该模型与筛查工具结合起来时,我们就为临床医生提供了一种非常有前途的方法。”
刘教授认为,将该模型与筛查工具结合起来用于临床是切实可行的。
“这项工作的一个独特优势是,这种临床信息学方法可以很容易地纳入到临床流程中,”刘说。“该预测模型可以嵌入医院的电子健康记录系统,该系统用于记录患者的健康状况,作为临床决策支持工具,标记高危儿童,以便临床医生和家庭可以更快采取行动。”
陈和惠特尼·格思里合作,临床心理学家他是费城儿童医院自闭症研究中心的主任,也是宾夕法尼亚大学佩雷尔曼医学院的精神病学和儿科助理教授。bob电竞
他们正在精确分析综合医院记录数据和筛查结果对自闭症诊断的预测效果,并探索其他潜在的筛查工具,以更好地帮助临床医生帮助他们的患者。
Guthrie说:“不仅目前的工具遗漏了许多自闭症谱系中的儿童,而且由于我们有限的诊断能力,许多被我们的筛查工具检测到的儿童需要等待很长时间。”
“虽然M-CHAT确实检测到了很多儿童,但它的假阳性和假阴性率也很高,这意味着许多自闭症儿童被遗漏,而其他儿童可能不需要进行自闭症评估时被转介去做评估。这两个问题都导致进一步的评估需要等待很长时间,通常需要数月甚至数年。”
“对于被我们当前筛查工具遗漏的儿童来说,其后果尤为重要,因为延迟诊断往往意味着儿童完全错过了早期干预的机会。儿科医生需要更好的筛查工具,以便尽早准确地识别出所有需要自闭症评估的儿童。”
部分原因是能够对自闭症谱系障碍进行诊断的心理学家、发育儿科医生和其他儿科发育专家数量有限。据陈教授介绍,解决方案可能存在于工业工程.
“关键的想法是改善我们如何使用资源,”陈说。“有了Guthrie博士的临床专业知识和我们团队的建模能力,我们的目标是开发一种工具初级保健医生没有经过专门培训的人可以进行自信的评估,以便尽早诊断儿童,以便尽快得到他们所需的护理。”