的许多表现COVID长

过去三年,它变得清晰,对许多人来说,SARS-CoV-2感染的影响持续很久之后的最初病例COVID-19减弱。
像主COVID-19,苦难,被称为急性后遗症的SARS-CoV-2 COVID (PASC)或长,有高度可变的持续时间、症状和严重程度。数据积累,长COVID似乎是一个严重的公共卫生问题,短时间内不会消失。
仍然没有被广泛接受的长COVID病例定义,但它通常指一系列持续的或新的症状仍然存在超过4周后最初的感染。部分原因是重要的个案差异,临床社会时间才意识到这是一个特定的条件,但代码(“Post-COVID-19条件”)实施诊断10月1日,2021年。代码允许病人被正式诊断为长期COVID医生诊断是进入电子健康记录(EHR)系统。
杰克逊实验室的Peter Robinson教授,医学博士、理学硕士和博士前的准本·科尔曼已经调查长COVID使用EHR数据从全美医疗系统作为国家的一部分COVID群组协作(N3C)。通过引入诊断代码,他们和他的同事们分析临床资料的患者诊断为长COVID更好地定义它的特征。他们还试图确定是否可以识别和定义亚型在尚未知之甚少伞诊断。他们的研究结果,提出了“Generalisable长COVID亚型:发现来自美国国立卫生研究院N3C和恢复项目”发表在eBioMedicine,表明长COVID确实出现在不同的亚型,它可以帮助将病人和通知治疗策略。
长COVID亚型
,罗宾逊和团队的20532名患者能够获得数据收到官方Post-COVID-19状况诊断,从38数据合作伙伴。虽然这个数字很低数据超过540万COVID-19 N3C平台数据库中的患者,2022年8月——队列长COVID研究是非常重要的因为他们都收到医生的诊断,他们都有相关的临床数据。研究人员长期COVID定义为呈现后28天最早COVID-19日期以门诊病人和结束后28天住院病人的住院治疗。
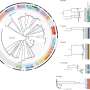
团队绘制了临床研究可计算的条款包含在人类表型本体(HPO),一个标准的框架来描述人类的特征,开发并维护了罗宾逊实验室。这使得研究人员分析数据在整个队列。调整计算算法被称为Phenomizer之后,他们能够确定对病人之间的相似性度量。进一步的计算显示病人的分组分成六个不同的集群,每个代表一个不同的长COVID亚型。定义的子类型是主要临床表现:
- 多系统+实验室(与严重最初的感染和高频率的多个症状:神经精神、肺,宪法(例如,常规疲劳),心血管,眩晕和实验室测试异常);
- 低氧血症和咳嗽;
- 神经(头痛、失眠、抑郁、运动异常);
- 心血管疾病;
- 疼痛/疲劳;和
- Multi-system-pain(类似于1没有实验室的结果)。
每个集群都有不同的年龄、性别和种族与之关联的频率,以及不同之前的并发症和条件。
精密长COVID治疗
研究结果强调长COVID的可能性机制可能不同个体之间基于基线风险因素的集合。的临床研究,如美国国立卫生研究院的“研究COVID加强恢复(恢复),“可能需要定义sub-cohorts努力识别候选疗法。和前进,分层长COVID病人将为有效的治疗是很重要的,因为它是怀疑任何一个方法将概括整个亚型。
更多信息:贾斯汀·t·里斯et al, Generalisable长COVID亚型:发现来自美国国立卫生研究院N3C和恢复项目,eBioMedicine(2022)。DOI: 10.1016 / j.ebiom.2022.104413,www.thelancet.com/journals/ebi…(22) 00595 - 3 /全文