老鼠用最初的奖励换取长期的学习机会
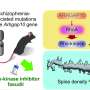
 Rat initiates trial by licking center port, one of two visual stimuli appears on the screen, rat chooses correct left/right response port for that stimulus and receives a water reward. (b) Speed-accuracy space: a decision making agent’s ER and mean normalized DT (a normalization of DT based on the average timing between one trial and the next, see Methods). Assuming a simple drift-diffusion process, agents that maximize iRR (see Methods) must lie on an optimal performance curve (OPC, black trace) (Bogacz et al., 2006). Points on the OPC relate error rate to mean normalized decision time, where the normalization takes account of task timing parameters (e.g. average response-to-stimulus interval). For a given SNR, an agent’s performance must lie on a performance frontier swept out by the set of possible threshold-to-drift ratios and their corresponding error rates and mean normalized decision times. The intersection point between the performance frontier and the OPC is the error rate and mean normalized decision time combination that maximizes iRR for that SNR. Any other point along the performance frontier, whether above or below the OPC, will achieve a suboptimal. iRR Overall, iRR increases toward the bottom left with maximal instantaneous reward rate at error rate = 0.0 and mean normalized decision time = 0.0. (c) Mean performance across 10 sessions for trained rats (n=26 ) at asymptotic performance plotted in speed-accuracy space. Each cross is a different rat. Color indicates fraction of maximum instantaneous reward rate (iRR ) as determined by each rat’s performance frontier. Errors are bootstrapped SEMs. (d) Violin plots depicting fraction of maximum, iRR a quantification of distance to the OPC, for same rats and same sessions as c. Fraction of maximum iRR is a comparison of an agent’s current iRR with its optimal iRR given its inferred SNR. Approximately 15 of 26 (∼60%) of rats attain greater than 99% fraction maximum iRRs for their individual inferred SNRs. * denotes p 0.99. Credit: eLife (2023). DOI: 10.7554/eLife.64978")
科学家为大鼠学习的认知控制提供了证据,表明它们可以估计学习的长期价值,并调整自己的决策策略,以利用学习机会。
研究结果表明,如果花更长的时间做决定,老鼠可能会牺牲即时奖励来提高他们的学习成果,并在整个任务过程中获得更大的奖励。研究结果今天发表在eLife.
行为神经科学的一个既定原则是速度-准确性的权衡,这在从啮齿动物到灵长类动物的许多物种中都可以看到。这一原则描述了一个人愿意缓慢反应和少犯错误与他们愿意迅速反应和冒更多错误的风险之间的关系。
“这一领域的许多研究都集中在速度-准确性的权衡上,而没有考虑学习结果,”主要作者Javier Masís说,他当时是美国哈佛大学分子与细胞生物学系和脑科学中心的博士生,现在是美国普林斯顿大学普林斯顿神经科学研究所的总统博士后研究员“我们的目的是调查当你有可能通过学习来改善你的行为时,存在的困难的跨期选择问题。”
在他们的研究中,Masís和同事们首先试图确定老鼠是否能够解决速度和准确性之间的权衡。研究小组做了一个实验,让老鼠在看到两个大小和旋转不同的视觉物体之一时,判断这个视觉物体对应的是左反应还是右反应,一旦它们做出决定,就会舔舐相应的触摸敏感端口。如果老鼠舔到了正确的端口,它们就会得到水的奖励,如果它们舔到了错误的端口,它们就会被暂停。
研究小组调查了错误率(ER)与反应时间(RT)在这些试验中,使用漂移扩散模型(DDM) -心理学和神经科学中的标准决策模型,在这个模型中,决策者随着时间积累证据,直到一个替代方案的证据水平达到阈值。
受试者的阈值水平控制着速度与准确度之间的权衡。使用低阈值会产生快速但容易出错的响应,而使用高阈值会产生缓慢但准确的响应。然而,对于每个难度级别,都有一个最佳阈值,以最佳地平衡速度和准确性,允许决策者最大化瞬时奖励率(iRR)在困难的情况下,这种行为可以通过ER和RT之间的关系来概括,称为最佳性能曲线(OPC)。在完全学习任务后,经过训练的大鼠中有一半以上达到了OPC,这表明训练有素的大鼠解决了速度和准确性之间的权衡。
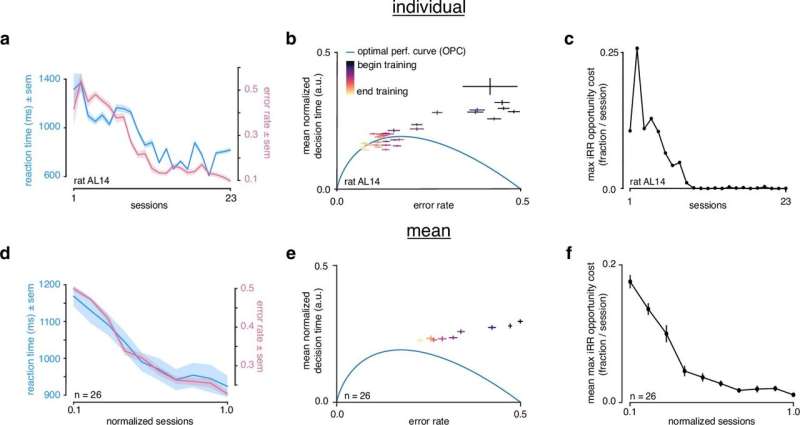
然而,在训练开始时,所有大鼠都放弃了超过20%的iRR,而在训练结束时,大多数大鼠接近最佳的iRR最大化。这就提出了一个问题:如果大鼠在学习结束时最大化瞬时奖励,那么在学习开始时是什么控制着它们的策略?
为了回答这个问题,该团队将DDM作为一种可以随时间学习的循环神经网络(RNN),并开发了学习漂移-扩散模型(LDDM),使他们能够研究许多试验中的长期感知学习是如何受到个别试验中决策时间选择的影响的。
该模型在设计时考虑到了简单性,以突出学习速度和决策策略之间的关键定性权衡。该模型的分析表明,大鼠采用了一种“非贪婪”策略,用初始奖励来优先学习,从而在任务过程中最大化总奖励。他们还证明,在实验和模拟环境中,较长的初始反应时间会导致更快的学习和更高的奖励。
作者呼吁进一步的研究来巩固这些发现。目前的研究受到使用DDM来估计改进学习的限制。DDM和LDDM是一个简单的模型,是一个强大的理论工具,用于理解可以在实验室中研究的特定类型的简单选择行为,但它不能定量描述更自然的决策行为。此外,本研究着重于一个视觉知觉任务;因此,作者鼓励进一步研究跨越困难、感觉模式和生物体的其他可学习任务。
“我们的研究结果提供了一个关于速度-准确性权衡的新观点,它表明感性决策行为强烈地受到快速学习的严格要求的影响,”资深作者Andrew Saxe声称,他之前是英国牛津大学实验心理学系的博士后研究助理,现在是英国伦敦大学学院盖茨比计算单元和Sainsbury Wellcome中心的Henry Dale爵士研究员和副教授。
哈维尔Masís解释说:“我们的研究提出的一个关键原则是,自然智能体考虑到这样一个事实,即它们可以通过学习来提高,并且它们可以通过自己的选择来塑造这种提高的速度。我们生活的世界不仅是非静止的;我们也是不固定的,我们在世界各地进行选择时,会考虑到这一点。”
萨克斯补充道:“你学钢琴不是靠偶尔弹弹琴键。“你决定练习,你的练习是以牺牲其他更直接的有回报的活动为代价的,因为你知道你会进步,最终可能是值得的。”
更多信息:哈维尔Masís等人,在感性决策过程中战略性地管理学习,eLife(2023)。DOI: 10.7554 / eLife.64978