人工智能预测未来的胰腺癌
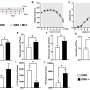
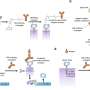
, a development set (Dev) and a test set (Test). The trajectories for training input are generated by sampling continuous subsequences of diagnoses for each patient’s diagnosis history, each starting with the first record but with different endpoints. The training and development sets are used for training so as to minimize the prediction error—that is, the difference between a risk score function (prediction) and a step function (observation), summed over all instances. Prediction: A model’s ability to accurately predict is evaluated using the withheld test set. The prediction model, depending on the prediction threshold selected from among possible operational points, discriminates between patients at higher and lower risk of pancreatic cancer. The risk model can guide the development of surveillance initiatives. b, The model trained with real-world clinical data has three steps: embedding, encoding and prediction. The embedding machine transforms categorical disease codes and timestamps of these disease codes into a lower-dimensional real number continuous space. The encoding machine extracts information from a disease history and summarizes each sequence in a characteristic fingerprint in the latent space (vertical vector). The prediction machine then uses the fingerprint to generate predictions for cancer occurrence within different time intervals after the time of assessment (3, 6, 12, 36 and 60 months). The model parameters are trained by minimizing the difference between the predicted and the observed cancer occurrence. c, Terminology for timepoints and intervals. The last event of a disease trajectory coincides with the time of assessment. From the time of assessment, cancer risk is assessed within 3, 6, 12, 36 and 60 months. To test the influence of close-to-cancer diagnosis codes on the prediction of cancer occurrence, exclusion intervals are used to remove diagnoses in the last 3, 6 and 12 months before cancer diagnosis. Credit: Nature Medicine (2023). DOI: 10.1038/s41591-023-02332-5")
一个人工智能工具已成功确认人胰腺癌风险最高的使用仅仅三年前诊断病人的医疗记录,根据新的研究由哈佛医学院研究人员和哥本哈根大学,与波士顿医疗保健系统的合作,丹娜-法伯癌症研究所,和哈佛T.H.成龙公共卫生学院。
研究结果发表在5月8日自然医学,表明基于ai人口筛查可以在寻找那些有价值的风险升高的疾病,可以加快诊断条件发现往往在晚期治疗更有效和结果惨淡时,研究人员说。胰腺癌症是世界上最致命的癌症之一,和它的人数吗预计将增加。
目前,没有以人群为基础的工具广泛筛选胰腺癌。那些有家族病史和某些基因突变使他们易罹患胰腺癌的筛查目标的方式。但这种有针对性的检查可以小姐以外的其他情况下,这些类别,研究人员说。
“最重要的决定之一,临床医生面临每天是谁是高危疾病,以及谁将受益于进一步测试,这也意味着更多的入侵和昂贵的过程,把自己的风险,”研究文章的第二研究员克里斯•桑德系的教员Blavatnik学院HMS系统生物学。“一个人工智能工具,可以瞄准那些风险最高的胰腺癌从中受益最多进一步测试可以很长一段时间来提高临床决策。”
应用于规模,桑德补充说,这种方法可以加快检测胰腺癌,导致早期治疗,改善结果,延长病人的寿命。
“许多类型的癌症,尤其是难以早期发现和治疗,对病人产生不成比例的人数、家庭和医疗体系作为一个整体,”研究文章的第二调查员Søren椰子饼,疾病系统生物学和教授的研究主任诺和诺德基金会在哥本哈根大学的蛋白质研究中心。“基于ai的筛选是一个机会改变胰腺癌的轨迹,咄咄逼人的疾病,是出了名的难以早期诊断和及时治疗,成功的几率是最高的。”
在新的研究中,人工智能算法在两个单独的数据集训练总计900万份病历从丹麦和美国。研究人员“问”人工智能模型寻找蛛丝马迹基于记录中包含的数据。根据疾病的代码和组合这些事件发生的时间,该模型能够预测哪些病人在未来可能患胰腺癌。值得注意的是,许多的症状和疾病编码并不直接相关或源于胰腺。
研究人员测试了不同版本的人工智能模型的能力检测在疾病发展风险在不同时间内scales-6几个月,一年,两年,三年。
总体来看,每个版本的人工智能算法大大更准确预测谁会比目前的全民发展胰腺癌的估计疾病incidence-defined频率条件发展人口在一个特定的时间。研究人员说他们相信模型至少是尽可能准确的预测疾病发生是当前基因测序的测试通常只能对一小部分病人在数据集。
“愤怒的器官”
筛查的某些常见的癌症如乳腺癌、宫颈癌、前列腺依赖于相对简单和高效的技术乳房x光检查,子宫颈抹片检查,分别和血液测试。这些筛选方法改变了结果对这些疾病通过确保早期检测和干预最可治疗阶段。
相比之下,胰腺癌是筛选和测试更为艰难,也更为昂贵。医生主要是看家庭历史的存在基因突变,尽管未来风险的重要指标,经常错过许多病人。人工智能工具的一个特定的优势是它可以用于任何和所有病人健康记录和病史,不仅在那些已知的家族史或疾病的遗传倾向。
这是特别重要的,研究人员增加,因为许多高危患者甚至可能不会意识到自己的遗传易感性或家族史。
没有症状,没有明确的迹象表明有人在胰腺癌的高危,临床医生可能可以理解谨慎推荐更复杂和更昂贵的测试,如CT扫描、MRI或内镜超声检查。当使用这些测试和发现可疑病变,病人必须经过一个过程获得活检。定位腹部深处,器官很难访问和容易引发和加剧。易怒赢得了它的绰号“愤怒的器官。”
一个人工智能工具,识别那些风险最高的胰腺癌将确保临床试验正确的人口,而保留其他不必要的测试和额外的过程,研究人员说。
约有44%的人在胰腺癌的早期诊断的诊断后存活5年,但只有12%的情况下是早期的诊断。存活率下降2 - 9%的肿瘤已经超出了他们的起源,研究人员估计。
“是存活率较低,尽管外科技术的进步,化疗,免疫疗法,”桑德说。“那么,除了复杂的治疗,有明确需要更好的筛选,更有针对性的测试,和早期诊断,这基于ai的方法的由来这个连续体的关键的第一步。”
前诊断预示着未来的风险
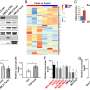
在当前的研究中,研究人员设计了几个版本的人工智能模型和训练他们的健康记录620万例来自丹麦的国家卫生系统生成41年。胰腺癌患者23985发达。培训期间,该算法分辨模式表明基于疾病轨迹未来胰腺癌的风险,也就是说,病人是否有一定的条件下,随着时间的推移发生在一个特定的序列。
例如,胆结石等诊断,贫血,2型糖尿病,和其他胃肠相关问题预示着更大的3年内胰腺癌的风险评估。更令人惊讶的是,胰腺炎强烈预测未来的胰腺癌在一个更短的时间跨度两年。
研究人员提醒说,这些诊断本身应该被视为象征或未来胰腺癌的病因。然而,随着时间的推移发生的模式和顺序为一个基于ai监测模型提供的线索,可能促使医生更为密切地监视那些风险升高或测试。
接下来,研究人员测试表现最好的算法一组全新的病人记录它以前从未遇到了一个美国退伍军人健康管理局近300万条记录的数据集生成包含3864人诊断为21年胰腺癌。工具的预测精度低,美国数据集。
这是最有可能的,因为美国数据集收集在更短的时间和包含一个不同的患者人群的所有丹麦人在丹麦数据集和现任和前任军人退伍军人事务数据集,该算法是从头开始重新训练的美国数据集,其预测精度得到了改善。
研究人员说,这凸显了两个要点:首先,确保人工智能模型训练的高品质和丰富的数据。第二,需要访问大代表数据集的聚合国内外临床记录。没有这样的在全球范围内有效的模型,人工智能模型应该在当地卫生训练数据以确保他们的培训反映了当地居民的特质。
更多信息:Søren椰子饼,深入学习算法从疾病轨迹预测胰腺癌的风险,自然医学(2023)。DOI: 10.1038 / s41591 - 023 - 02332 - 5。www.nature.com/articles/s41591 - 023 - 02332 - 5