机器学习模型发现心脏病的遗传因素

得到一个在看心脏,心脏病学家经常使用心电图(ecg)跟踪其电活动和磁共振图像(核磁共振成像)将其构造。因为这两种类型的数据显示不同细节的心,医生通常分别研究诊断心脏疾病。
现在,在发表的一篇论文自然通讯埃里克·施密特和温迪中心,科学家在麻省理工和哈佛大学已经开发出一种机器学习方法同时从ecg和核磁共振成像,可以学习模式,并基于这些模式,预测病人的特点心。这样一个工具,随着进一步的发展,有一天可以帮助医生更好的检测和诊断心脏病等常规检测ecg。
研究还表明,他们可以分析心电图记录,容易和廉价收购,并生成核磁共振电影相同的心,更昂贵的捕捉。甚至他们的方法可以被用来寻找新的心脏病的遗传标记,现有的方法,看个人数据模式可能会错过。
总的来说,研究小组称他们的技术是一个更全面的方法来研究心脏疾病。“很明显,这两个观点,ecg和核磁共振成像,应当整合,因为它们提供不同角度的状态的心,”卡罗琳Uhler说,这项研究文章的第二作者,一个广泛的核心机构成员,施密特联合中心广泛,和教授的电气工程和计算机科学研究所以及数据,系统和麻省理工学院的社会。
“作为一个领域,心脏病很幸运有很多诊断模式,每提供一个不同的观点到心脏生理健康和疾病。我们面临的挑战是,我们缺乏系统化的工具将这些形式集成到一个单一的、连贯的图片,”安东尼Philippakis说高级研究报告合著者和首席数据官广泛和施密特联合中心。“这项研究代表了一个第一步建立这样一个综合描述。”
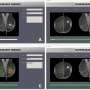
 on the latent representations. c Our framework enables translation between modalities: ECGs can be translated to corresponding MRIs and vice-versa. d The learned cross-modal representations can be used to understand genotype-phenotype maps in the absence of labeled phenotypes by performing a GWAS in the cross-model latent space and clustering SNPs via their signatures (i.e., the vector in latent space oriented from homozygous reference to the mean of heterozygous and homozygous alternate); SNPs 1 and 4 have similar signatures in the latent space and thus similar phenotypic effects. Credit: Nature Communications (2023). DOI: 10.1038/s41467-023-38125-0")
模型制作
开发他们的模型,研究人员使用一种叫做autoencoder机器学习算法,它自动将巨大的数据集成到一个简洁的图形表示简单形式的数据。团队使用这种表示方法为其他机器学习模型作为输入,使具体的预测。
在他们的研究中,研究小组首先训练autoencoder使用ecg和心脏核磁共振成像从英国生物库的参与者。在成千上万的ecg,每个搭配MRI图像的同一个人。算法然后创建共享表示,从这两种类型的数据捕获的关键细节。
“一旦你有了这些表示,您可以使用它们对许多不同的应用程序来说,“Adityanarayanan Radhakrishnan说co-first作者的一项研究中,一个埃里克施密特和温迪中心研究员广泛,和麻省理工学院的一名研究生在Uhler实验室。山姆·弗里德曼的高级机器学习科学家广泛数据科学平台,是另一个co-first作者。
这些应用程序之一是预测心脏方面的特征。研究人员使用表示由他们autoencoders构建一个模型,该模型可以预测的一系列特征,包括功能的心脏左心室的重量,其他病人特征与心脏功能诸如年龄、甚至心脏疾病。此外,他们的模型比更标准的机器学习方法,以及autoencoder算法训练只是成像模式之一。
“我们这里显示是你获得更好的预测精度包含多种类型的数据,“Uhler说。
Radhakrishnan解释说,他们的模型作出了更为准确的预测,因为它使用表示更大的数据集训练。Autoencoders不需要数据标记的人类,因此,团队可以喂养autoencoder大约有39000标记对ecg和MRI图像,而不是5000年左右成对的标签。
研究人员演示了他们的另一个应用程序autoencoder:产生新的核磁共振电影。通过输入一个人的心电图记录到产生的模型,而无需配对MRI记录模型预测的核磁共振电影为同一人。
更多的工作,科学家们设想,这种技术可能会让医生了解病人的心脏健康从心电图记录,定期收集在医生的办公室。
更广泛的基因搜索
autoencoder表示,团队意识到他们也可以使用它们来寻找与心脏疾病相关的遗传变异。传统方法寻找基因变异的疾病,称为全基因组关联研究(GWAS),需要从个体遗传数据被标以感兴趣的疾病。
但是因为团队的autoencoder框架不需要带安全标签的数据时,他们能够产生表示,反映了病人的整体状态的心。使用这些表征和基因数据英国生物库在同一患者,研究人员创建了一个模型,寻找基因变异影响心脏的国家在更一般的方法。产生的模型变量的列表包括许多已知的变异与心脏病和一些新的,现在可以进一步调查。
Radhakrishnan说,基因发现可能的区域autoencoder框架,更多的数据和发展,可能最影响心脏疾病,但对于任何疾病。研究小组已经在应用他们的autoencoder框架来研究神经系统疾病。
Uhler说这个项目是一个很好的例子,如何创新生物医学数据分析出现当机器学习人员与生物学家和医生合作。“一个令人兴奋的方面得到机器学习生物医学研究人员感兴趣的问题是,他们可能会提出一个全新的看待问题的方式。”
更多信息:Adityanarayanan Radhakrishnan et al,跨通道autoencoder框架学习整体表现的心血管状态,自然通讯(2023)。DOI: 10.1038 / s41467 - 023 - 38125 - 0