大脑中重现结果可以预测我们是否方法或避免的情况
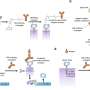
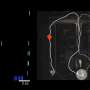
 All 12 stimuli used in the experiment. Six stimuli were pseudo-randomly allocated to each participant, per session, ensuring equal allocation of each stimulus. (b) For visualization purposes, stimuli are represented by letters: A, B, and C for path 1, and D, E, and F for path 2. In an initial functional localiser in session 2, participants viewed an image and then reported the correct label (left or right). Correct and incorrect responses produced a green or red fixation cross, respectively. (c) To learn the image order, participants selected either Path 1 or Path 2 (forced-choice, 2 selections of each) and then observed an animation of the sequence of states along each path. Participants were then tested on their memory for the image order. (d) After image learning, participants observed the animated sequences again but this time with the value of each state displayed underneath each image. Participants were tested on their memory for the values associated with each state, as well as their ability to calculate the cumulative sum at different states. (e) Two protocols were used, counterbalanced across participants. One such protocol is shown. The designation of the odd rule to one state per path (first row) dictated the final value of each path (second row). One path was mostly negative (here, starting with path 1; circles) and the other mostly positive (here, starting with path 2; triangles), with the exception of catch trials (marked in yellow). This tendency switched halfway through the experiment. The transition probability (third row) to each path, in combination with the path value, dictated the expected value of approaching (fourth row). Expected value was a sum of each path’s value weighted by its probability. When the expected value was greater than 1 (which was guaranteed outcome of avoiding), participants should approach (green); otherwise, participants should avoid (red). Credit: Nature Neuroscience (2023). DOI: 10.1038/s41593-023-01287-7")
过去的神经科学研究表明,在决定下一步行动时,老鼠和其他啮齿动物往往重演过去的结果类似的情况下在他们的大脑,这是反映在一个快速激活大脑某些区域的序列。最近,一些研究类似replay-associated记录大脑活动在人类大脑使用成像技术。
伦敦大学学院(UCL)研究人员进行的一项研究探索的可能性,这种快速“重播”过去的积极和消极的结果可以预测,人类做出的选择的情况他们可以失去或获得钱。他们的发现发表在自然神经科学,推出可能联系回放在人类的大脑和行为计划,表明虽然选择方法或避免的情况,人类精神代表最糟糕的情况的目的,这也源于自己的选择。
”这个作品的灵感来自于许多新发现了大脑中关于“回放”,“杰西卡·McFadyen的研究人员进行的这项研究,对医学Xpress。bob游戏“啮齿动物往往重放路径对奖励(计划去哪里),但也往往重放路径,可能会导致一个电击(计划不去)。所以,当我们不确定会发生什么路径导致奖励或惩罚吗?这就是我感兴趣的。”
McFadyen最近研究的关键目标和她的同事刘Yunzhe和雷蒙德·j·多兰是考察不同路径重播在人类的大脑在结果的情况下不容易演绎。具体地说,他们检测了场景中,人类可能矛盾是否接近给定路径,或避免进退两难冲突回避冲突。
“选择是否保持(避免)或(方法)是很困难的,当我们不确定,和有可能重演在大脑中最终可以解释我们如何弥补我们的思想,“McFadyen说。“为了验证这个假设,我们用大脑成像技术称为脑磁图描记术,这需要使用一台机器,坐落在头皮上拿起微小的电流通过人体神经元。”
脑磁图描记术允许研究人员精确测量大脑的不同区域的活动,当他们发生。McFadyen和她的同事专门用它来测量大脑活动的非常快破裂发生在大脑在重播,相距只有40毫秒。
25他们记录的活动参与者被要求参加一个简单的游戏地图。在这个游戏中,参与者与不同的场景中,他们不得不选择是否接近或避免特定的路径。
“路径只是图像序列,参与者学习序列将结束与积极点(奖金钱)或消极点(没有奖金的钱),“McFadyen解释道。“一个关键因素是,如果参与者选择的方法,他们可能无法得到他们想要的路径。总有一些概率(例如,30%的机会),他们会发送到一个更加危险的道路。尽管参与者审议是否冒这个险,我们占领了大脑活动最感兴趣,即与回放期间回避冲突的冲突。”
他们收集了他们的大脑录音后,研究人员利用机器学习来分析,确定哪些图片他们曾面对的重播在大脑中,参与者做了一个新的决定。换句话说,他们使用的模型检测的序列再活跃大脑的活动,第一次记录,而参与者最初呈现一个给定的图像。
通过分析这些结果结合决策参与者(即。,他们是否接近或避免特定情况下),McFadyen和她的同事被能够确定序列被重播前参与者决定或避免给定路径的方法。
“我们最大的发现是,人类影响路径的最糟糕的情况下,“McFadyen说。“如果参与者最终决定要完全避免,他们倾向于重放(或者说“模拟”)路径导致所需但放弃奖励。另一方面,如果参与者最终决定方法和冒险,他们倾向于重放路径导致害怕负面的结果。这种反向思考可能是大脑的一种方式,以确保我们不要忘记选择的结果。”
这组研究人员收集的研究结果提供了一些有趣的新想法关于人类过去的经历在他们的大脑,然后再决定是否重放方法或避免某些情况。在未来,他们可以通知其他作品探索回放和决策之间的联系,同时也可能提高我们对问题的理解与回避性行为焦虑性障碍和其他精神疾病。
“有很多这项研究可能需要我们的地方,“McFadyen补充道。”一个大道将进一步研究如何更好地衡量的重播人类的大脑,因为它是具有挑战性的可靠措施即使机器学习。另一个途径是然后进一步研究如何回放与负模拟的过去和未来,抑郁和焦虑方面起到了关键的作用。如果我们更好地理解的大脑这些模拟发生,以及如何自发或控制它们,然后我们可以更好的指导精神卫生治疗方法。”
更多信息:杰西卡McFadyen et al,微分的奖励和惩罚的路径预测方法和避免,自然神经科学(2023)。DOI: 10.1038 / s41593 - 023 - 01287 - 7
©2023科学BOB体育赌博X网络