ChatGPT医药相关查询的反应从那些由人类几乎无法分辨

ChatGPT回应人民的卫生保健相关查询提供从那些由人类几乎无法分辨,纽约大学的一项研究经脉工程学院和格罗斯曼医学院的揭示,提出潜在的聊天机器人是有效的盟友医疗服务提供者与病人沟通。
纽约大学的研究小组提出了392人年龄在18岁及以上十个病人和响应的问题,有一半的人类的医疗服务提供者所产生的反应,ChatGPT另一半。
参与者被要求识别每个响应和评价他们的来源信任ChatGPT反应使用潜油电泵规模从完全不值得信任,完全值得信赖。
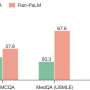
研究发现人们区分chatbot和的能力有限人类生成响应。平均参与者正确识别65.5%的chatbot响应时间和供应商响应时间的65.1%,与49.0%到85.7%的范围不同的问题。结果保持一致,无论人口类别的受访者。
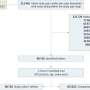
研究发现参与者温和信任聊天机器人的反应总体(3.4平均分数),较低的信任当与卫生相关的任务的复杂性问题是高。后勤方面的问题(例如安排预约、保险问题)信任评级最高(3.94平均分数),其次是预防保健(如疫苗、癌症筛查、3.52平均得分)。诊断和治疗建议信任评级最低(得分分别为2.90和2.89)。
研究人员称,该研究凸显了可能性,聊天机器人可以协助patient-provider沟通特别相关的管理任务和常见的慢性病管理。进一步的研究是必要的,然而,在聊天机器人的承担更多的临床作用。供应商应保持谨慎和运动规划时关键的判断聊天机器人生成的建议由于人工智能模型的局限性和潜在的偏见。
的研究中,把ChatGPT医疗建议的(图灵)测试:调查研究,”发表在JMIR医学教育。
更多信息:欧迪11月et al, ChatGPT医疗建议的(图灵)测试:调查研究中,JMIR医学教育(2023)。DOI: 10.2196/46939
所提供的纽约大学经脉工程学院
引用医药相关查询:ChatGPT反应几乎无法分辨的从那些由人类(2023年7月14日)2023年7月14日从//www.pyrotek-europe.com/news/2023-07-chatgpt-responses-healthcare-related-queries-indistinguishable.html检索
本文档版权。除了任何公平交易私人学习或研究的目的,没有书面许可,不得部分复制。内容只提供信息的目的。